CIS307: Bridges, Routers, Gateways
A Bridge is a box with ports (usually two) to LAN segments. It operates in promiscuous mode at the data link layer (i.e. at the level of frames, not signals), it examines all frames and it recognizes where they came from, and where they are going to. It selectively (frame filtering) transfers frames from any port to other ports. It does not propagate noise signals and defective frames as it was the case for repeaters (at the physical layer). It adaptively recognizes which machines are reacheable from a port. It reduces traffic on each port and it improves security since each port will only transmit frames directed to nodes reacheable from that port (thus one does not overhear irrelevant traffic).
Bridges are normally used to connect LAN segments within a limited geographic area (local bridges), like a building or a campus. But they are also used in the network of an enterprise to interconnect LANs: a bridge in a LAN is connected through some long distance channel (for example, a line provided by a common carrier) to a bridge in a distant LAN (remote bridges). Usually bridges connect segments using the same data link protocol, but some modern bridges can convert between different data link protocols (for example, ethernet and token ring).
Bridges can be transparent (usually in Ethernet lans),
also called spanning tree bridges,
where the aim is to minimize
all work required to set up a bridge and have instead
the hardware and software set up the bridge with the information
required for routing frames correctly.
Or bridges can be source routing bridges (usually in token ring lans)
where the route from sender to receiver are preset at the sender and
included in the frame.
We will only discuss transparent bridges.
All the nodes reacheable from a node through segments and bridges
will receive broadcast messages sent by that node. They constitute the
broadcast domain of the given node.
Bridges are able to filter frames on the basis of any information available at the data link level in the frame. For example, since an Ethernet frame has a field with information about the higher level protocol used in the data portion of the frame, a bridge could be programmed to filter out frames that use selected protocols.
The algorithm is run independently at each bridge.
It makes the natural assumption: If a frame from a node
j is received through port i then messages to j will go
out through i.
It keeps a cache of pairs of the form [i,j]
where i is a port (of the current bridge) and j
is the address of a node (usually an ethernet address)
reacheable from the current bridge through port i.
This cache is initially empty.
When the bridge receives a frame from a port i it determines the
physical addresses of its source, j, and of its destination, k.
If k is a multicast address, then the frame is forwarded through
all the ports except the one through which it was received
(flooding).
If the pair [i,j] is not already in the cache, it is added to it.
If [i,k] is in the cache then
the frame is discarded.
else if there is a pair [h,k] in the cache then
the frame is forwarded through port h
else
it is forwarded to all ports (flooding) except i.
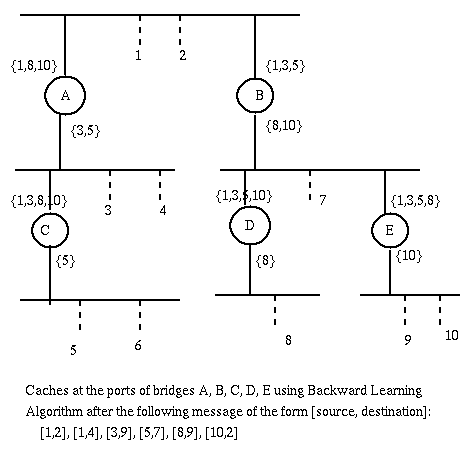
This algorithm does not assume any knowledge on the part of a bridge about the structure of the network. It just uses the address information in the frames about senders and receivers.
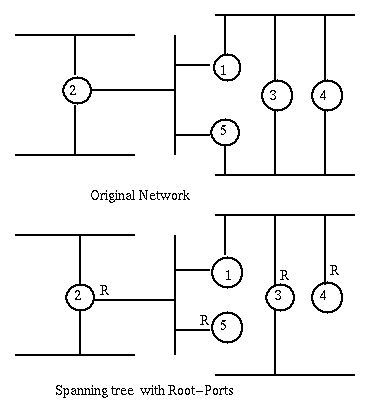
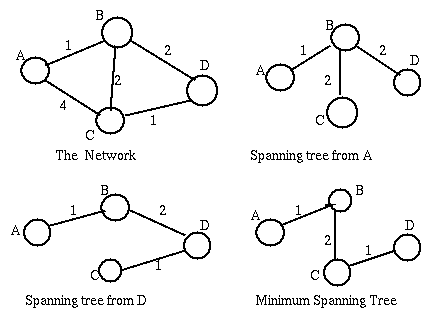
The intent of the Distributed Spanning Tree Algorithm is to identify the node (i.e. bridge) with smallest id, the root-bridge of the network; Then for every other node, to identify the port, root-port, through which goes the shortest path to the root-bridge. Finally for every lan segment to choose the bridge in the shortest path to the root-bridge, the designated bridge of the segment, and the port through which that segment accesses that bridge, the designated port. The spanning tree will include only the bridge ports that are either root-ports or designated-ports. For example, if we take as cost of a path the number of bridges it traverses, the following network is changed as indicated.
The Distributed Spanning Tree Algorithm is interesting as an example of the kind of algorithm that works in a distributed environment where no node has full knowledge of the network. Later in the course we will discuss more in detail the difficulties that arise in distributed environments.
In the Distributed Spanning Tree Algorithm bridges exchange messages using the standard set by IEEE 802.1. These messages, called configuration messages, use multicasting to a multicast group consisting of all and only the bridges on the same segment as the transmitting bridge. These messages are sent at network power-up to acquire information on the network topology, and then again whenever changes in topology are detected. Note that these configuration messages represent control traffic, that is overhead. A configuration message identifies, among other things:
Initially each bridge sends a configuration message on each of its ports. This message has this port's id as root-bridge and as transmitter and has 0 as cost. This message is saved at each port as "best" configuration for that port and for the bridge. When a message is received at a port, if the received message is better than the current best configuration of the port, it becomes the new best configuration of this port and, if it becomes the port with the best configuration, it is said to be the root-port of the bridge and to be active. [The root-port leads to the root-bridge and the first bridge next on that path acts as the designated bridge of the current bridge.] The best configuration of the root-port, if better than the best configuration of the bridge, with the transmitting bridge field set to this bridge, and the cost incremented by one, is set as best configuration of the bridge. Then this new best configuration is compared to the best configurations of all the ports. If the best configuration of a port of a bridge is worse than the best configuration of a bridge, the port it is said to be active, and the best configuration is transmitted through that port. [In reality if a port is to go from the inactive to the active state, this transition will be delayed some time to make sure that other ports that were supposed to go from active to inactive have actually done so. This is required to avoid transient loops between bridges.] The ports that are not the root port, and have not been made active, become inactive. The Spanning Tree consists of the bridges and their active ports and the segments thus connected.
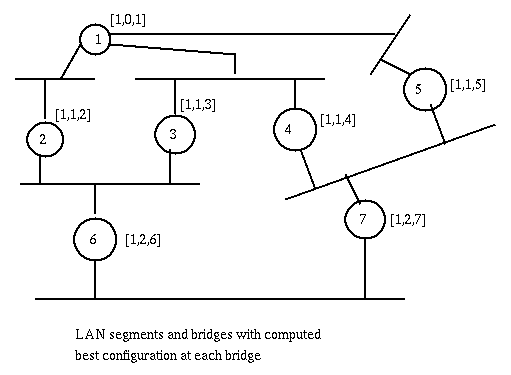
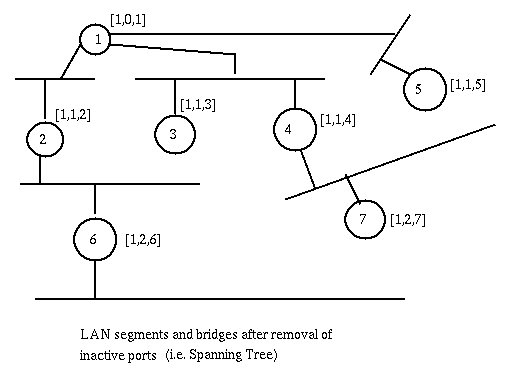
Each stored configuration message keeps an extra field representing the age of the message, i.e. the time since the root bridge sent the configuration message upon which this message is based. It is incremented each unit of time (timer-tick, usually 2 seconds) and when it reaches a preset maximum value maxAge (usually 20 seconds), the stored configuration for the port is reset to the initial value (current bridge as root bridge and source, cost and age set to 0). Then at this bridge is recomputed the best configuration (and root, cost to root, and root-port), thus another previously inactive port can become active. The root bridge sends at regular intervals Hello-time an Hello-message to the bridges for which it is the designated bridge. When a bridge receives the Hello message it resets the age field for the receiving port to 0 and forwards its own configuration with age set to zero to the bridges for which it is the designated bridge. [maxAge should be larger than Hello-time plus the propagation time for the hello messages from the root to all the nodes in the spanning tree.]The effect of the hello message from the root bridge is to eliminate reconfiguration unless necessary.
Evaluation of Routing Algorithms:
Routing protocol characteristics:
We consider two routing algorithms, one centralized (the full topology of the network is know at each router), Dijkstra's shortest path algorithm, and one distributed (a router only knows its neighbors), the vector distance routing algorithm. We do not worry at this time about protocols or standards used for exchanging routing information.
Initialize arrays R and D so that for each vertex v of the graph, R[v] = NIL,
and D[v] is infinity except for s where D[s] = 0.
Finally let the set S consist of all the vertices of the graph.
While S is not empty
Let u be an element of S with minimal D value and remove it from S.
For each element v in the neighborhood of u
Let w be D[u] + cost-of-edge[u,v];
If D[v] is greater than w then
Set D[v] to w;
Set R[v] to u;
Then for all vertices v, D[v] is the cost of the paths from s to v
(or viceversa) and R[v] is the next node (next-hop) in the optimal
path from v to s (or viceversa).
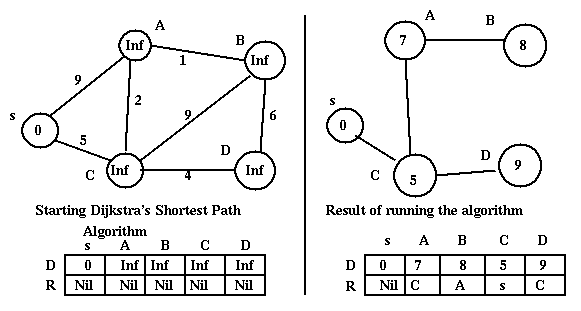
Note that Dijkstra's Algorithm creates a spanning tree with as root the node where the algorithm is run (s in the discussion above). The algorithm will result in different trees when run at different nodes. These spanning trees are not necessarily minimal (i.e. the sum of the cost of the branches is not minimal). For example:
Now each vertex s only knows itself, its neighbors, and the distance to
these neighbors. Each vertex keeps a set of triples of the form
[destination, next-hop, distance]. This set is the distance vector.
Initially this set is {[s,NIL,0]} and it is transmitted to each neighbor.
When a vertex u receives a distance vector from its neighbor v
For each triple [d,n,c] in the received distance vector
Let w = c + distance from u to neighbor v
If there is no triple of the form [d,x,y] in the distance
vector of u or
there is such a triple and (y > w or x=v) then
Remove [d,x,y], if there, and add [d,v,w] to the distance
vector of u.
When a vertex u recognizes that the link to a neighbor v has failed
Requests distance vector information from its remaining neighbors and
Recalculate the distance vector using the new neighborhood information.
A vertex sends a copy of its distance vector to its neighbors
whenever there has been a change in its own distance vector
or a failure in its neighborhood
Here is what the Vector Distance Algorithm
does in the case of the graph above:
Step 0:
s {[s,nil,0]}
A {[A,nil,0]}
B {[B,nil,0]}
C {[C,nil,0]}
D {[D,nil,0]}
Step 1:
s {[s,nil,0],[A,A,9],[C,C,5]}
A {[A,nil,0],[s,s,9],[B,B,1],[C,C,2]}
B {[B,nil,0],[A,A,1],[C,C,9[,[D,D,6]}
C {[C,nil,0],[s,s,5],[A,A,2],[B,B,9],[D,D,4]}
D {[D,nil,0],[C,C,4],[B,B,6]}
Step 2:
s {[s,nil,0],[A,C,7],[B,A,10],[C,C,5],[D,C,9]}
A {[A,nil,0],[s,C,7],[B,B,1],[C,C,2],[D,C,6]}
B {[B,nil,0],[s,A,10],[A,A,1],[C,A,3],[D,D,6]}
C {[C,nil,0],[s,s,5],[A,A,2],[B,A,3],[D,D,4]}
D {[D,nil,0],[s,C,9],[A,C,6],[C,C,4],[B,B,6]}
Step 3:
s {[s,nil,0],[A,C,7],[B,C,8],[C,C,5],[D,C,9]}
A {[A,nil,0],[s,C,7],[B,B,1],[C,C,2],[D,C,6]}
B {[B,nil,0],[s,A,8],[A,A,1],[C,A,3],[D,D,6]}
C {[C,nil,0],[s,s,5],[A,A,2],[B,A,3],[D,D,4]}
D {[D,nil,0],[s,C,9],[A,C,6],[C,C,4],[B,B,6]}
A problem with the distance vector algorithm is its slowness in propagating the recognition of link failures (it is called the count to infinity problem). For example in the following graph
+---+ +---+ +---+
| A |----------| B |-----------| C |
+---+ +---+ +---+
suppose that we have the following distance vectors:
At A: {[A,NIL,0], [B,B,1], [C,B,2]}
At B: {[A,A,1], [B,NIL,0], [C,C,1]}
At C: {[A,B,2], [B,B,1], [C,NIL,0]}
and the link from B to C fails. So B discards the triple
[C,C,1] and recomputes the vector using the information from
A, thus it adds the triple [C,A,3]. This change in turn
is propagated to A that has to change its C triple to
[C,B,4], that causes B to change to [C,A,5], .. and so on
until "infinity" is reached and A and B can finally conclude that
C is unreacheable!
Note that we say that Dijkstra's algorithm is centralized because it requires the collection of global information about the graph. In the Distance Vector algorithm instead we need only information about the local neighborhood of a vertex.
Routing algorithms, i.e. algorithms used for computing routing tables, are implemented using routing protocols. Examples of such protocols are RIP (Routing Information Protocol), EGP (Exterior Gateway Protocol), IGRP (Interior Gateway Routing Protocol). The packets exchanged in the routing protocols are called routing packets and they contain control information, i.e. they are overhead. ICMP (Internet Control Message Protocol) is a protocol used to propagate echo and reply messages that test the reacheability of nodes in the network, and to report loss of packets due to time expiration. IRDP (ICMP Router Discovery Protocol) is used to identify routers and to report their identity.