 CIS 307: Introduction to Distributed Systems II
CIS 307: Introduction to Distributed Systems II
 CIS 307: Introduction to Distributed Systems II
CIS 307: Introduction to Distributed Systems II
In discussing algorithms in a distributed environment we can distinguish 2+1 cases:
The -> relation is a partial order. Given events e1 and e2 it is not true that either they are the same or one happened-before the other. Events that are not ordered by happened-before are said to be concurrent.
This characterization of happened-before is unsatisfactory since, given two events, it is not immediate (think of the time it takes to evaluate a transitive relation) to determine if one happened before the other or if they are concurrent. We could like a clock C that applied to an event returns a number so that the following holds:
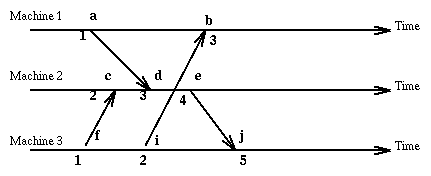
Since the method we have chosen allows different events (on different machines) to have the same logical clock value, we extent the clock value with a number representing the machine where the event occurred [i, C(e)] and order these pairs according to the rule:
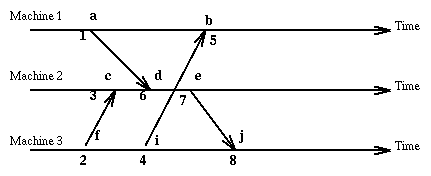
Here is our old example using vector clock values.
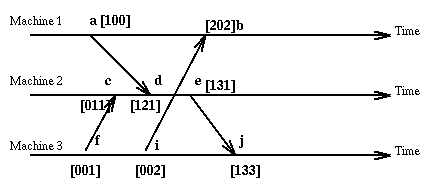
Of course nothing is perfect. So the use of vector clocks results in big time stamps and requires that we know in advance the identities of the sites involved.
I am on a computer system and I want to transfer $100 to your account. So I reduce my account by $100 and send you a message announcing the deposit. When you receive the message, you increment your balance. But during the time the message is in transit by looking simultaneously to your account and my account we find that they are painting the wrong picture. That is, the states that are visible in the two different systems should be as if no message were ever in transit. [Another way of saying this would be to say that the withdrawal/deposit should form an atomic transaction.] If we call local state the content of variables at a site (i.e. its state), global state a vector with as components the local states in the distributed system being considered, and consistency between two distinct local states the fact that the corresponding sites do not have messages in transit, then a consistent global state is one whose component local states are pairwise consistent. For many applications it would be desireable to do things so that the global state is consistent. Equally desireable is to be able to record successive consistent global states (Think of debugging, where we are trying to reconstruct at a central site the sequence of states taking place at the distributed locations.)
Useful for determining a global state, and for other communication purposes, it is to have a messaging system where messages satisfy a pipeline property: if m1 and m2 are messages and we have SEND(m1) -> SEND(m2) then RECEIVE(m1) -> RECEIVE(m2). When this property is satisfied we have a natural ordering (partial) for messages, called causal ordering of messages: m1 -> m2 if SEND(m1) -> SEND(m2). Note that the following situations are forbidden in a messaging system with the pipeline property:

Algorithms are available for converting a messaging system without the pipeline property into one where the property is satisfied. [They force delaied acceptance of messages until the pipeline property is satisfied.]
Here is how a client would operate
..........
Send request to M
Wait for reply from M
Use resource R
Send release notice to M
..........
This means that each use of the resource will have as overhead 3 messages.
If W is the time we use the resource and T is the time taken by each message
then the total time spent for a critical region is (W+3T) and the maximum
rate of use of the resource with a single user
is 1/(W+3T). Of course W/(W+3T) is the maximum
utilization possible with one user for the resource.
With multiple users requests can occur while the resource is being used,
thus we can have the utilization W/(W+2T). If we can have broadcasting
of messages, then we can select the next user while the resource is
being used. Thus we can utilization W/(W+T).
Now we look at what is done by the manager M:
It uses two variables:
resourceIsFree, a boolean indicating state of resource, initially true;
rqueue, a FIFO queue containing pending requests;
loop {
wait for a message;
if the message is a request {
if resourceIsFree {
allocate resource to requestor;
set resourceIsFree to false;
} else
insert request in rqueue;
} else /* it is a release */
if rqueue is empty
set resourceIsFree to true;
else {
remove a request from rqueue;
send reply to that requestor;}
}
Of course we are in trouble if the Manager dies. Firstly we do not
know its current state (i.e., the state of the resource and who
is waiting), second, we don't have a coordinator anymore. For the second
problem we hold an election to select new manager. For the first problem,
each process has to recognise failure and adjust accordingly [each process
knows its own state and can communicate it to the new manager].
self: the identity of this process (a number like 7);
localClock: an integer representing a local logical clock (initially 0);
highestClock: an integer, the largest clock value seen in a request
(initially 0);
need: an integer representing number of replies needed before self
can enter the critical region;
pending: a boolean array with n entries; entry k (k!=self) is true
iff process Pk has made a request and process self has not responded;
the self entry is true if process self wants to enter critical region;
s: a blocking semaphore used to hold the processing thread while the
comunication thread takes care of synchronization.
mutex: a mutual exclusion semaphore used to protect pending.
loop {
wait for a message;
if the message is a request {
let k be the identity of requestor and c the clock on message;
set highestClock to max(highestClock, c);
P(mutex);
if (pending[self] and ([self,localClock] < [k, c]))
set pending[k] to true;
V(mutex);
else
V(mutex):
send response to k;
} else { /* the message is a reply */
decrement need by 1;
if need is 0
V(s);}
}
P(mutex);
set pending[self] to true;
V(mutex);
set localClock to highestClock + 1;
set need to n-1;
send to all other processes a request stamped with [self, localClock];
P(s);
CRITICAL REGION
set pending[self] to false;
for k from 1 to n {
P(mutex);
if pending[k] and k != self {
send response to k;
set pending[k] to false;}
V(mutex);
This algorithm, due to Ricart-Agrawala has been extended by Raymond to the
case where more that 1 process can be in the critical region at one time and
to the case where requests are for multiple copies of a resource.
In the case that we do not have a ring communication topology, we can still achieve mutual exclusion using the concept of token. The algorithm is due to Chandy.
We have n processes P1, .., Pn. The token contains a vector [T1,..,Tn] where Ti is the number of times that process Pi has been in the critical region. Each process Pi has the variables:
loop {
wait for a message;
P(mutex);
if (withToken is true){
if (count of requestor on message is greater than on token) {
send token to requestor;
set withToken to false;}
/* else the message is discarded */
} else {
insert it into rqueue;}
V(mutex);
}
.................
send request time stamped [i,mi] to all other processes;
wait for token;
CRITICAL REGION
set mi in token to mi+1;
set Ti to mi;
P(mutex);
while rqueue is not empty {
dequeue a request, say, time stamped [j, mj];
if mj < Tj {
it is a stale request; throw it away;
} else {
send toKen to jth processor;
break;
}
if token was not sent out
set withToken to true;
V(mutex);
.................
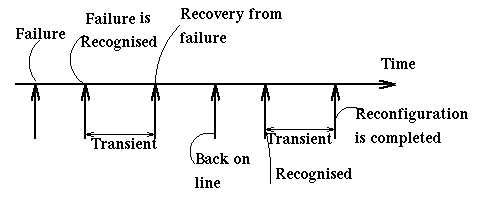
The following figure shows the time relations between the time of failure, the time the failure is recognized, and the time when the system has reconfigured itself to deal with the failure. The time between the recognition of failure and the completion of reconfiguration is a transient. We have a transient also when a node comes back on line and the system has to reconfigure itself. Things can get exciting (i.e. dangerous) when the two transients overlap.
We can reason as follows with generals A and B. A sends a message to B suggesting "attack at 7am". When A receives agreement from B, it attacks at 7am. The problem is, how does B know that A has received agreement? he cannot thus he does not attack at 7am. So may be A on receiving agreement from B it sends an acknowledgement to B. But then A will not know if B has received the acknowledgement and it will not attack at 7am. There is no solution with a finite sequence of messages. If there were, the last general to send a message would not know if the other general has received that message. Thus that last message cannot be necessary for the agreement, thus the sequence was not minimal. Contradiction. Loyal generals, in the case of unreliable communication cannot reach absolute certainty on when to attack. Consensus cannot be achieved reliably in the presence of al unreliable communication system.
For atomic database operations we assume that an operation is requested with appropriate parameters, and at some point later we are told by the database if the operation was committed (i.e. done) or aborted. The operations are atomic, serializable and persistent [just as defined for atomic transaction in Tanenbaum]. Examples of atomic operations are deposit (i.e. increment and write), withdrawal (i.e. decrement and write), and balance (i.e. read). The execution of atomic database operations can be concurrent as long as the atomicity, serializability, and persistence properties are satisfied. For example, we may have, assuming that location x contains $100:
REQUEST-DEPOSIT(1,X,$100) REQUEST-BALANCE(2,X) REPORT-COMMIT-BALANCE(2,$100) REPORT-COMMIT-DEPOSIT(1)or
REQUEST-DEPOSIT(1,X,$100) REQUEST-BALANCE(2,X) REPORT-COMMIT-BALANCE(2,$200) REPORT-COMMIT-DEPOSIT(1)meaning that for the same two requests, the balance can be assumed as being computed either before or after the deposit.
Often people refer to the desired properties of transactions using the ACID acronym:
Assuming that we are given atomic database operations we want to be able to implement reliably atomic transactions such as:
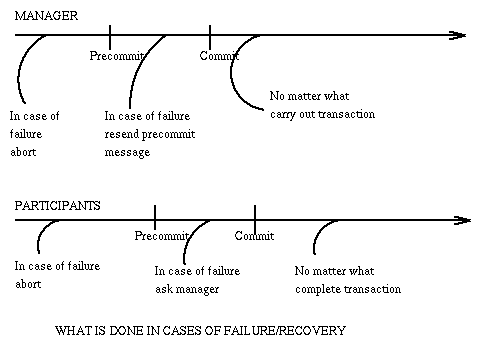
Let's consider the Two-Phase Commit Protocol. The problem is the following: A number of systems are involved in the transaction. One is the transaction manager, say system 1. All other systems have a resource manager that is responsible for carrying out the local operations keeping a local log and communicating with the (transaction) manager. Each system has available stable storage to record reliably their progress and decisions across temporary local failures and recoveries. We assume that communication is reliable and we accept the fact that any system may fail and recover. We want to reach the situation where all systems complete in agreement that the transaction is committed (and they all are in the new state) or that it is aborted (and they all are in the old state). Of course the agreement should be faithful to the truth: there is commitment iff all systems will complete their tasks.
Part 1:
Carry out the operations of the transaction in
an undo-able fashion [for example, keep a log
of all that is done with "before" and "after" values
so that to undo we just go backwards replacing
"after" values by "before" values. In this way
it will be possible to "redo" or "undo" an action
if it is so desired].
Agreement Protocol:
The manager writes a pre-commit record to the log (stable storage)
and sends to all others the request that they
report their decision:
Round 1:
All systems write a pre-commit or abort record to
the log (stable storage) and report to the manager
their local decision to commit or abort.
The manager collects the answers [if any is late, it
assumed to be an abort] then decides to commit iff
all replies were to commit. [The decision is recorded
in stable storage at the manager with a commit record.]
Round 2:
The manager informs all systems of the decision and
they are to carry out that decision. [The manager
will keep sending the decision until it
is recorded in stable storage at all systems.]
Part 2:
The actions are finalized at all systems. This can be accomplished
reliably since what to do is recorder in stable storage
at each site.
The protocol requires 3(n-1) messages, where n is the number of systems.
Note that people think of the two phases as referring to Part 1 and
Part 2, while in reality the two phases refer to the two rounds of
the agreement protocol. Note also that the protocol is imperfect since
it assumes that no system will fail permanently. Consider the case that system
j fails permanently after round 1 when all had agreed to commit.
Then the manager decides to commit and informs the others in Part 2
but the transaction cannot complete since system j is not there to
accept the message from the manager, and the manager cannot abort because
by now some systems have finalized their action. It is also a problem if
the manager fails permanently at the end of round one, just before
recording its decision. The other systems that have failed will know what to do
[abort, thus re-establishing the previous state],
but those that had decided to commit are in trouble [they are left hanging
on how to finalize the transaction]. So some additional work, not part of the
protocol, needs to be done to handle these problems.
Basically, we need to have some way of knowing when we can close the
books on a transaction and say that it is done.
A three-phase commit protocol has been suggested to deal
with the weaknesses of the two-phase protocol.

ingargiola.cis.temple.edu