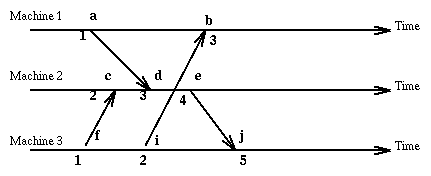
We would like to order the events occurring in a distributed system in such a way as to reflect their possible causal connections. Certainly if an event A happens before an even B, then A cannot have been caused by B. In this situation we cannot say that A is the directed cause of B, but we cannot exclude that A might have influenced B. We want to characterize this "happened-before" relation on events. We will consider only two kinds of events, the sending of a message and the receiving of a message.
The -> relation is a partial order. Given events e1 and e2 it is not true that either they are the same event or one happened-before the other. These events may be unrelated. Events that are not ordered by happened-before are said to be concurrent.
This characterization of happened-before is unsatisfactory since, given two events, it is not immediate (think of the time it takes to evaluate a transitive relation) to determine if one event happened before the other or if they are concurrent. We would like a clock C that applied to an event returns a number so that the following holds:
Since the method we have chosen allows different events (on different machines) to have the same logical clock value, we extent the clock value with a number representing the machine where the event occurred [i, C(e)] and order these pairs according to the rule:
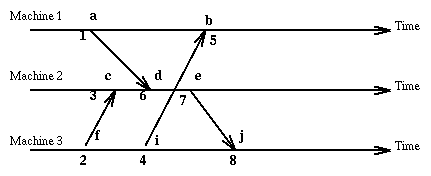
Here is our old example using vector clock values.
Of course nothing is perfect. Though vector clocks allow to represent faithfully the happened before relation between events, they result in big time stamps and requires that we know in advance the number and identities of the sites involved.
All logical clocks, whether scalar or vector, suffer of a basic problem:
though they represent that an even occurred (or not) before another, they do not
represent before by how much, that is, there is no measure of elapsed
time. In particular we cannot use logical clocks for timeouts, we need instead
a wallclock (i.e. an old fashioned clock, possibly synchronized).
Another problem of logical clocks, even vector clocks, is that they cannot account
for information exchanged outside of the computer systems, say because user A at system 1
receives output from the system and says that information to user B at system 2. And now user B
enters that information at system 2.
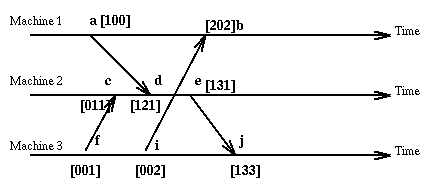
Algorithms are available for converting a messaging system without the causal property into one where the property is satisfied. In the example above we see that the message at event f on machine 3 has timestamp [1,0,0] while the last event e on machine 3 had timestamp [2,2,1]. Thus we know that the message received at f was sent before the sending of the message received at e. This does not help us directly since by now the message at e has been accepted. But if we require that all messages be broadcast, then each machine will be able to detect if a message is received out of order as shown in the following graph
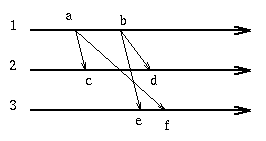
now the message at e is received with timestamp [2,0,0] while the local clock is [0,0,0] thus we know that an event on machine 1 that preceded the sending of this message was not received on machine 3. Consequently we can postpone at machine 3 the delivery of the e message until after the f event has occurred.
We talk of total ordering of (multicast) messages if they are received everywhere in the same order.
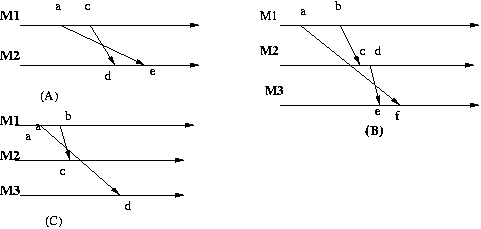
Important is also the concept of Consistent Cut, that is a cut across the timelines of the computers in the distributed system, such that there is no event a at computer i that is after the cut, and event b at computer j that is before the cut, yet a happened-before b. For example in the diagram below, the first and second cuts are consistent, while the third is not.
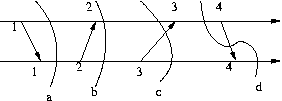
A consistent cut ( a set of events) corresponds to a state
in the distributed system which can be explained on the basis of the events that
occurred up to that time, there is no evidence in one system of something
caused in another system, and not yet seen. This is necessary for
reasonable debugging and for all situations where we want to be able
to observe the evolution of the state of a distributed system.
If a set of events (a cut) is inconsistent then there is an event e' in the set
and an event e not in the set such that e -> e'.
You may remember that in the transaction to transfer $100 from account A
to account B, there is a time when the $100 are out of A but not yet
in B (or viceversa). The money is like "in transit", or, this is the
preferred term, "in the [communication] channel". When we look for
consistent cuts (or states), we look for situations where either
nothing is in the channel, or where we know what is in the channel.
Chandy and Lamport have an algorithm for computing consistent global
states (also called snapshots). A system decided to start a
snapshot: it saves its state and sends a Marker out through its outgoing
links. When a system receives a marker for the first time, it saves its
state and sends the marker out through its outgoing links. It will also
save the messages it receives on an in link until it receives a marker on
that link. The algorithm terminates when each node has received markers
through all its in links. The global state consists of the state at the
nodes plus the messages stored by the nodes.
Given a computer that has a local physical clock that has drift d (i.e., it will have a maximum error d after one second), if we want it to have an error betweek the clocks of two machines (i.e. the difference, called skew, between the hardware clocks of the two systems at one instant] that is never greater than e, we can do it by requesting a UTC time server for the correct time every e/2d seconds (the factor 2 accounts for the fact that the drift can slow down or speed up the local physical clock). The Christian's Algorithm implements this idea. Here are two potential problems with this algorithm, together with their solution.
The are an unlimited number of uses for synchronized physical clocks and for logical clocks. Among them,